Welcome to a quick tutorial on how to get the HTML code from websites. Is there a certain website that you find interesting? Want to know how it works behind the scenes? Or maybe you just need to email a part of the website to someone.
In most modern browsers, there are a few ways we can use to get the HTML code from websites:
- View the source code of the web page – Press
control-uon Windows, andcommand-uon a Mac. - Inspect the web page – Right-click anywhere on the webpage, and inspect.
- Save the web page – Press
control-son Windows, andcommand-son a Mac.
Just how exactly does each one of these work? Read on the find out!
TABLE OF CONTENTS
HOW TO GET HTML CODE

All right, let us now get into the various ways to grab HTML code from a website.
1) VIEW THE SOURCE CODE
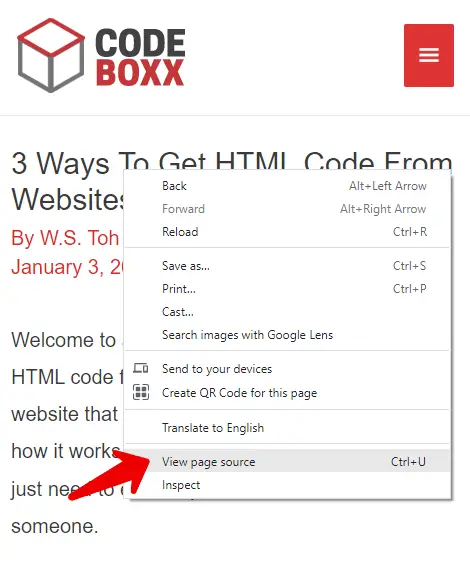
This is probably the most common method, recommended by everyone all over the Internet. Right-click anywhere on the webpage > View source. Or simply hit the shortcut key CTRL-U (COMMAND-U on a Mac).
Please take note that depending on which web browser you are using, this is going to be slightly different – It is called “view page source” on Google Chrome and Firefox, and “view source” on Microsoft Edge… But they all do the same thing.
2) INSPECT ELEMENT (DEVELOPER’S CONSOLE)
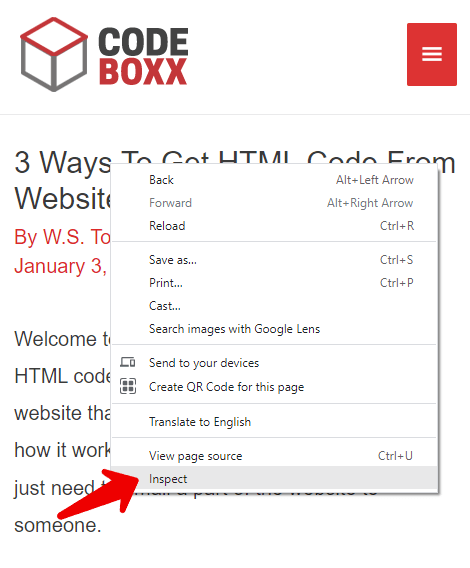
Some of you guys should have noticed the “inspect” option under “view source”, so go ahead and try it out. Right-click on anything on the webpage > Inspect. Yep, this opens up the developer’s console and gives you a full view of the rendered HTML.
Some of you guys may cringe at this method, thinking it is “too technical”, but no… This is actually a way better method than just “view source”. We will get more into that below.
3) SAVE THE PAGE
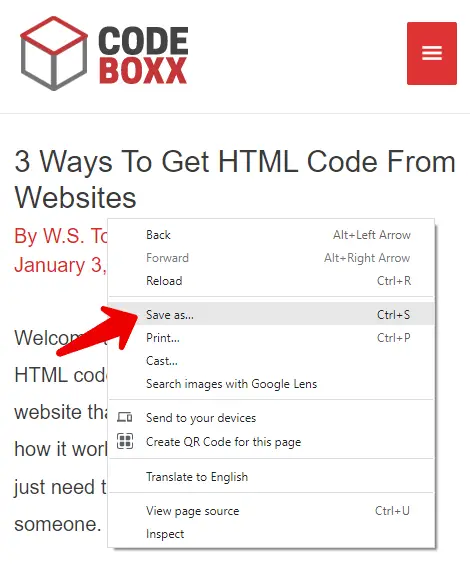
I think you guys should be experts by now. Right-click anywhere on the page > Save as. The shortcut key is CTRL-S (or COMMAND-S on a Mac). One small thing to take note though –

The webpage will be saved to an HTML file and all the assets (images, sound, video) will be saved into a corresponding folder. This is kind of troublesome if you are trying to send the webpage to someone else. In this case, I will recommend to just sending the full URL, or taking a screenshot instead.
EXTRA BITS & LINKS

That’s all for this guide, and here is a small section on some extras and links that may be useful to you.
WHAT IS THE DIFFERENCE?
So which is the best method to use? Is there a difference between these methods at all? This may be kind of confusing, but each method will return wildly different results depending on how the webpage is built. Take a dynamic webpage as an example:
- The page will first load an “empty news feed” when you first visit.
- It will then dynamically load the contents into the news feed area.
- The page will load even more content into the news feed as you scroll down.
As to how the methods defer:
- View page source – This will only show you the empty news feed. That is the “original page” without dynamic content.
- Inspect – This will show you an accurate “whatever is rendered on the screen right now”.
- Save page – This will try to save a snapshot of the current page, but take note that not everything can be saved. Videos and sounds will probably be omitted, along with any ads.
FORMAT CODE
Is the HTML code too messy and difficult to read? Fear not, there are many online tools that can help you format them:
Just search for “format HTML online” and there will be a ton more.
LINKS & REFERENCES
- View the HTML source code of a web page – Computer Hope
- How To View the HTML Source in Google Chrome – Lifewire
- How to See the HTML Code of a Web Site – Chron
THE END

Thank you for reading, and we have come to the end of this guide. I hope that it has helped you with your project, and if you want to share anything with this guide, please feel free to comment below. Good luck and happy coding!